Lossless data compression
Lossless data compression is a class of data compression algorithms that allows the exact original data to be reconstructed from the compressed data. The term lossless is in contrast to lossy data compression, which only allows an approximation of the original data to be reconstructed, in exchange for better compression rates.
Lossless data compression is used in many applications. For example, it is used in the popular ZIP file format and in the Unix tool gzip. It is also often used as a component within lossy data compression technologies (e.g. lossless mid/side joint stereo preprocessing by the LAME MP3 encoder and other lossy audio encoders).
Lossless compression is used in cases where it is important that the original and the decompressed data be identical, or where deviations from the original data could be deleterious. Typical examples are executable programs, text documents and source code. Some image file formats, like PNG or GIF, use only lossless compression, while others like TIFF and MNG may use either lossless or lossy methods. Lossless audio formats are most often used for archiving or production purposes, with smaller lossy audio files being typically used on portable players and in other cases where storage space is limited and/or exact replication of the audio is unnecessary.
Contents |
Lossless compression techniques
Most lossless compression programs do two things in sequence: the first step generates a statistical model for the input data, and the second step uses this model to map input data to bit sequences in such a way that "probable" (e.g. frequently encountered) data will produce shorter output than "improbable" data.
The primary encoding algorithms used to produce bit sequences are Huffman coding (also used by DEFLATE) and arithmetic coding. Arithmetic coding achieves compression rates close to the best possible for a particular statistical model, which is given by the information entropy, whereas Huffman compression is simpler and faster but produces poor results for models that deal with symbol probabilities close to 1.
There are two primary ways of constructing statistical models: in a static model, the data is analyzed and a model is constructed, then this model is stored with the compressed data. This approach is simple and modular, but has the disadvantage that the model itself can be expensive to store, and also that it forces a single model to be used for all data being compressed, and so performs poorly on files containing heterogeneous data. Adaptive models dynamically update the model as the data is compressed. Both the encoder and decoder begin with a trivial model, yielding poor compression of initial data, but as they learn more about the data performance improves. Most popular types of compression used in practice now use adaptive coders.
Lossless compression methods may be categorized according to the type of data they are designed to compress. While, in principle, any general-purpose lossless compression algorithm (general-purpose meaning that they can compress any bitstring) can be used on any type of data, many are unable to achieve significant compression on data that are not of the form for which they were designed to compress. Many of the lossless compression techniques used for text also work reasonably well for indexed images.
Text
Statistical modeling algorithms for text (or text-like binary data such as executables) include:
- Context Tree Weighting method (CTW)
- Burrows-Wheeler transform (block sorting preprocessing that makes compression more efficient)
- LZ77 (used by DEFLATE)
- LZW
- PPMd
Multimedia
Techniques that take advantage of the specific characteristics of images such as the common phenomenon of contiguous 2-D areas of similar tones. Every pixel but the first is replaced by the difference to its left neighbor. This leads to small values having a much higher probability than large values. This is often also applied to sound files and can compress files which contain mostly low frequencies and low volumes. For images this step can be repeated by taking the difference to the top pixel, and then in videos the difference to the pixel in the next frame can be taken.
A hierarchical version of this technique takes neighboring pairs of data points, stores their difference and sum, and on a higher level with lower resolution continues with the sums. This is called discrete wavelet transform. JPEG2000 additionally uses data points from other pairs and multiplication factors to mix then into the difference. These factors have to be integers so that the result is an integer under all circumstances. So the values are increased, increasing file size, but hopefully the distribution of values is more peaked.
The adaptive encoding uses the probabilities from the previous sample in sound encoding, from the left and upper pixel in image encoding, and additionally from the previous frame in video encoding. In the wavelet transformation the probabilities are also passed through the hierarchy.
Historical legal issues
Many of these methods are implemented in open-source and proprietary tools, particularly LZW and its variants. Some algorithms are patented in the USA and other countries and their legal usage requires licensing by the patent holder. Because of patents on certain kinds of LZW compression, and in particular licensing practices by patent holder Unisys that many developers considered abusive, some open source proponents encouraged people to avoid using the Graphics Interchange Format (GIF) for compressing image files in favor of Portable Network Graphics PNG, which combines the LZ77-based deflate algorithm with a selection of domain-specific prediction filters. However, the patents on LZW have now expired.[1]
Many of the lossless compression techniques used for text also work reasonably well for indexed images, but there are other techniques that do not work for typical text that are useful for some images (particularly simple bitmaps), and other techniques that take advantage of the specific characteristics of images (such as the common phenomenon of contiguous 2-D areas of similar tones, and the fact that color images usually have a preponderance of a limited range of colors out of those representable in the color space).
As mentioned previously, lossless sound compression is a somewhat specialised area. Lossless sound compression algorithms can take advantage of the repeating patterns shown by the wave-like nature of the data – essentially using models to predict the "next" value and encoding the (hopefully small) difference between the expected value and the actual data. If the difference between the predicted and the actual data (called the "error") tends to be small, then certain difference values (like 0, +1, -1 etc. on sample values) become very frequent, which can be exploited by encoding them in few output bits.
It is sometimes beneficial to compress only the differences between two versions of a file (or, in video compression, of an image). This is called delta compression (from the Greek letter Δ which is commonly used in mathematics to denote a difference), but the term is typically only used if both versions are meaningful outside compression and decompression. For example, while the process of compressing the error in the above-mentioned lossless audio compression scheme could be described as delta compression from the approximated sound wave to the original sound wave, the approximated version of the sound wave is not meaningful in any other context.
Lossless compression methods
By operation of the pigeonhole principle, no lossless compression algorithm can efficiently compress all possible data, and completely random data streams cannot be compressed. For this reason, many different algorithms exist that are designed either with a specific type of input data in mind or with specific assumptions about what kinds of redundancy the uncompressed data are likely to contain.
Some of the most common lossless compression algorithms are listed below.
General purpose
- Run-length encoding – a simple scheme that provides good compression of data containing lots of runs of the same value.
- LZW – used by gif and compress among others
- Deflate – used by gzip, modern versions of zip and as part of the compression process of PNG, PPP, HTTP, SSH
Audio
- Waveform audio format - WAV
- Free Lossless Audio Codec – FLAC
- Apple Lossless – ALAC (Apple Lossless Audio Codec)
- apt-X Lossless
- ATRAC Advanced Lossless
- Audio Lossless Coding – also known as MPEG-4 ALS
- MPEG-4 SLS – also known as HD-AAC
- Direct Stream Transfer – DST
- Dolby TrueHD
- DTS-HD Master Audio
- Meridian Lossless Packing – MLP
- Monkey's Audio – Monkey's Audio APE
- OptimFROG
- RealPlayer – RealAudio Lossless
- Shorten – SHN
- TTA – True Audio Lossless
- WavPack – WavPack lossless
- WMA Lossless – Windows Media Lossless
Graphics
- JBIG2 – (lossless or lossy compression of B&W images)
- JPEG-LS – (lossless/near-lossless compression standard)
- JPEG 2000 – (includes lossless compression method, as proven by Sunil Kumar, Prof San Diego State University)
- JPEG XR - formerly WMPhoto and HD Photo, includes a lossless compression method
- PGF – Progressive Graphics File (lossless or lossy compression)
- PNG – Portable Network Graphics
- TIFF - Tagged Image File Format
- Gifsicle (GPL) Optimize gif files
- Jpegoptim (GPL) Optimize jpeg files
3D Graphics
- OpenCTM – Lossless compression of 3D triangle meshes
Video
- Animation codec
- CorePNG
- Dirac - Has a lossless mode.[2]
- FFV1
- JPEG 2000
- Huffyuv
- Lagarith
- MSU Lossless Video Codec
- SheerVideo
Cryptography
Cryptosystems often compress data before encryption for added security; compression prior to encryption helps remove redundancies and patterns that might facilitate cryptanalysis. However, many ordinary lossless compression algorithms introduce predictable patterns (such as headers, wrappers, and tables) into the compressed data that may actually make cryptanalysis easier. Therefore, cryptosystems often incorporate specialized compression algorithms specific to the cryptosystem—or at least demonstrated or widely held to be cryptographically secure—rather than standard compression algorithms that are efficient but provide potential opportunities for cryptanalysis.
Lossless compression benchmarks
Lossless compression algorithms and their implementations are routinely tested in head-to-head benchmarks. There are a number of better-known compression benchmarks. Some benchmarks cover only the compression ratio, so winners in these benchmark may be unsuitable for everyday use due to the slow speed of the top performers. Another drawback of some benchmarks is that their data files are known, so some program writers may optimize their programs for best performance on a particular data set. The winners on these benchmarks often come from the class of context-mixing compression software. The benchmarks listed in the 5th edition of the Handbook of Data Compression (Springer, 2009) are:[3]
- The Maximum Compression benchmark, started in 2003 and frequently updated, includes over 150 programs. Maintained by Werner Bergmans, it tests on a variety of data sets, including text, images and executable code. Two types of results are reported: single file compression (SFS) and multiple file compression (MFC). Not surprisingly, context mixing programs often wins here; programs from the PAQ series and WinRK often are in the top. The site also has a list of pointers to other benchmarks.[4]
- UCLC (the ultimate command-line compressors) benchmark by Johan de Bock is another actively maintained benchmark including over 100 programs. The winners in most test usually are PAQ programs and WinRK, with the exception of lossless audio encoding and grayscale image compression where some specialized algorithms shine.
- Squeeze Chart by Stephan Busch is another frequently updated site.
- The EmilCont benchmarks by Berto Destasio are somewhat outdated having been most recently updated in 2004. A distinctive feature is that the data set is not made public in order to prevent optimizations targeting it specifically. Nevertheless, the best ratio winner are again the PAQ family, SLIM and WinRK.
- The Archive Comparison Test (ACT) by Jeff Gilchrist included 162 DOS/Windows and 8 Macintosh lossless compression programs, but it was last updated in 2002.
- The Art Of Lossless Data Compression by Alexander Ratushnyak includes provides similar test performed in 2003.
Matt Mahoney, in his February 2010 edition of the free booklet Data Compression Explained, additionally lists the following:[5]
- The Calgary Corpus dating back to 1987 is no longer widely used due to its small size, although Leonid A. Broukhis still maintains the The Calgary Corpus Compression Challenge, which started in 1996.
- The Large Text Compression Benchmark and the similar Hutter Prize, both using a trimmed Wikipedia XML UTF-8 data set.
- The Generic Compression Benchmark, maintained by Mahoney himself, test compression on random data.
- Sami Runsas (author of NanoZip) maintains Compression Ratings, a benchmark similar to Maximum Compression multiple file test, but with minimum speed requirements. It also offers a calculator that allows the user to weight the importance of speed and compression ratio. The top programs here are fairly different due to speed requirement. In January 2010, the top programs were NanoZip followed by FreeArc, CCM, flashzip, and 7-Zip.
- The Monster of Compression benchmark by N. F. Antonio tests compression on 1Gb of public data with a 40 minute time limit. As of Dec. 20, 2009 the top ranked archiver is NanoZip 0.07a and the top ranked single file compressor is ccmx 1.30c, both context mixing.
Limitations
Lossless data compression algorithms cannot guarantee compression for all input data sets. In other words, for any (lossless) data compression algorithm, there will be an input data set that does not get smaller when processed by the algorithm. This is easily proven with elementary mathematics using a counting argument, as follows:
- Assume that each file is represented as a string of bits of some arbitrary length.
- Suppose that there is a compression algorithm that transforms every file into a distinct file which is no longer than the original file, and that at least one file will be compressed into something that is shorter than itself.
- Let
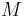 be the least number such that there is a file
be the least number such that there is a file  with length bits that compresses to something shorter. Let
with length bits that compresses to something shorter. Let  be the length (in bits) of the compressed version of .
be the length (in bits) of the compressed version of . - Because
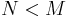 , every file of length keeps its size during compression. There are
, every file of length keeps its size during compression. There are  such files. Together with , this makes
such files. Together with , this makes 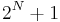 files which all compress into one of the files of length .
files which all compress into one of the files of length . - But is smaller than , so by the pigeonhole principle there must be some file of length which is simultaneously the output of the compression function on two different inputs. That file cannot be decompressed reliably (which of the two originals should that yield?), which contradicts the assumption that the algorithm was lossless.
- We must therefore conclude that our original hypothesis (that the compression function makes no file longer) is necessarily untrue.
Any lossless compression algorithm that makes some files shorter must necessarily make some files longer, but it is not necessary that those files become very much longer. Most practical compression algorithms provide an "escape" facility that can turn off the normal coding for files that would become longer by being encoded. Then the only increase in size is a few bits to tell the decoder that the normal coding has been turned off for the entire input. For example, DEFLATE compressed files never need to grow by more than 5 bytes per 65,535 bytes of input.
In fact, if we consider files of length N, if all files were equally probable, then for any lossless compression that reduces the size of some file, the expected length of a compressed file (averaged over all possible files of length N) must necessarily be greater than N. So if we know nothing about the properties of the data we are compressing, we might as well not compress it at all. A lossless compression algorithm is useful only when we are more likely to compress certain types of files than others; then the algorithm could be designed to compress those types of data better.
Thus, the main lesson from the argument is not that one risks big losses, but merely that one cannot always win. To choose an algorithm always means implicitly to select a subset of all files that will become usefully shorter. This is the theoretical reason why we need to have different compression algorithms for different kinds of files: there cannot be any algorithm that is good for all kinds of data.
The "trick" that allows lossless compression algorithms, used on the type of data they were designed for, to consistently compress such files to a shorter form is that the files the algorithms are designed to act on all have some form of easily-modeled redundancy that the algorithm is designed to remove, and thus belong to the subset of files that that algorithm can make shorter, whereas other files would not get compressed or even get bigger. Algorithms are generally quite specifically tuned to a particular type of file: for example, lossless audio compression programs do not work well on text files, and vice versa.
In particular, files of random data cannot be consistently compressed by any conceivable lossless data compression algorithm: indeed, this result is used to define the concept of randomness in algorithmic complexity theory.
An algorithm that is asserted to be able to losslessly compress any data stream is provably impossible[6]. While there have been many claims through the years of companies achieving "perfect compression" where an arbitrary number N of random bits can always be compressed to N-1 bits, these kinds of claims can be safely discarded without even looking at any further details regarding the purported compression scheme. Such an algorithm contradicts fundamental laws of mathematics because, if it existed, it could be applied repeatedly to losslessly reduce any file to length 0. Allegedly "perfect" compression algorithms are usually called derisively "magic" compression algorithms.
On the other hand, it has also been proven that there is no algorithm to determine whether a file is incompressible in the sense of Kolmogorov complexity; hence, given any particular file, even if it appears random, it's possible that it may be significantly compressed, even including the size of the decompressor. An example is the digits of the mathematical constant pi, which appear random but can be generated by a very small program. However, even though it cannot be determined whether a particular file is incompressible, a simple theorem about incompressible strings shows that over 99% of files of any given length cannot be compressed by more than one byte (including the size of the decompressor).
Mathematical background
Any compression algorithm can be viewed as a function that maps sequences of units (normally octets) into other sequences of the same units. Compression is successful if the resulting sequence is shorter than the original sequence plus the map needed to decompress it. In order for a compression algorithm to be considered lossless, there needs to exist a reverse mapping from compressed bit sequences to original bit sequences; that is to say, the compression method would need to encapsulate a bijection between "plain" and "compressed" bit sequences.
The sequences of length N or less are clearly a strict superset of the sequences of length N-1 or less. It follows that there are more sequences of length N or less than there are sequences of length N-1 or less. It therefore follows from the pigeonhole principle that it is not possible to map every sequence of length N or less to a unique sequence of length N-1 or less. Therefore it is not possible to produce an algorithm that reduces the size of every possible input sequence.
Psychological background
Most everyday files are relatively 'sparse' in an information entropy sense, and thus, most lossless algorithms a layperson is likely to apply on regular files compress them relatively well. This may, through misapplication of intuition, lead some individuals to conclude that a well-designed compression algorithm can compress any input, thus, constituting a magic compression algorithm.
Points of application in real compression theory
Real compression algorithm designers accept that streams of high information entropy cannot be compressed, and accordingly, include facilities for detecting and handling this condition. An obvious way of detection is applying a raw compression algorithm and testing if its output is smaller than its input. Sometimes, detection is made by heuristics; for example, a compression application may consider files whose names end in ".zip", ".arj" or ".lha" uncompressible without any more sophisticated detection. A common way of handling this situation is quoting input, or uncompressible parts of the input in the output, minimising the compression overhead. For example, the zip data format specifies the 'compression method' of 'Stored' for input files that have been copied into the archive verbatim.[7]
The Million Random Number Challenge
Mark Nelson, frustrated over many cranks trying to claim having invented a magic compression algorithm appearing in comp.compression, has constructed a 415,241 byte binary file ([1]) of highly entropic content, and issued a public challenge of $100 to anyone to write a program that, together with its input, would be smaller than his provided binary data yet be able to reconstitute ("decompress") it without error.[8]
The FAQ for the comp.compression newsgroup contains a challenge by Mike Goldman offering $5,000 for a program that can compress random data. Patrick Craig took up the challenge, but rather than compressing the data, he split it up into separate files all of which ended in the number '5' which was not stored as part of the file. Omitting this character allowed the resulting files (plus, in accordance with the rules, the size of the program that reassembled them) to be smaller than the original file. However, no actual compression took place, and the information stored in the names of the files was necessary in order to reassemble them in the correct order into the original file, and this information was not taken into account in the file size comparison. The files themselves are thus not sufficient to reconstitute the original file, the file names are also necessary. A full history of the event, including discussion on whether or not the challenge was technically met, is on Patrick Craig's web site.[9]
See also
- Audio data compression
- Comparison of file archivers
- David A. Huffman
- Information entropy
- Kolmogorov complexity
- Data compression
- Precompressor
- Lossy data compression
- Lossless Transform Audio Compression (LTAC)
- List of codecs
- Information theory
- universal code (data compression)
- Grammar induction
References
- ↑ Unisys | LZW Patent and Software Information
- ↑ http://etill.net/projects/dirac_theora_evaluation/#specPC
- ↑ David Salomon, Giovanni Motta, (with contributions by David Bryant), Handbook of Data Compression, 5th edition, Springer, 2009, ISBN 1848829027, pp. 16–18.
- ↑ Lossless Data Compression Benchmarks (links and spreadsheets)
- ↑ http://nishi.dreamhosters.com/u/dce2010-02-26.pdf, pp. 3–5
- ↑ comp.compression FAQ list entry #9: Compression of random data (WEB, Gilbert and others)
- ↑ ZIP file format specification by PKWARE, chapter V, section J
- ↑ Nelson, Mark (2006-06-20). "The Million Random Digit Challenge Revisited". http://marknelson.us/2006/06/20/million-digit-challenge/.
- ↑ Craig, Patrick. "The $5000 Compression Challenge". http://www.patrickcraig.co.uk/other/compression.htm. Retrieved 2009-06-08.
External links
- Comparison of Lossless Audio Compressors at Hydrogenaudio Wiki
- Comparing lossless and lossy audio formats for music archiving
- [2] — data-compression.com's overview of data compression and its fundamentals limitations
- [3] — comp.compression's FAQ item 73, What is the theoretical compression limit?
- [4] — c10n.info's overview of US patent #7,096,360, "[a]n "Frequency-Time Based Data Compression Method" supporting the compression, encryption, decompression, and decryption and persistence of many binary digits through frequencies where each frequency represents many bits."
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||